OpenOffice's Power Law Regression: Where Did It Come From?
I was poking around the source of OpenOffice 2.x the other day and I came across its equation regression package. Inside, there is a set of functions to support regressing to a power law function. I found the recalculateRegression() function very interesting. I broke down the math involved in this function’s operation to the following:
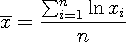
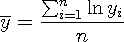
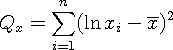
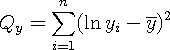
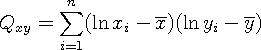
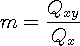
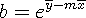
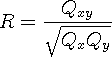
…where m is the slope, b is the intercept and R is the coefficient of correlation.
I checked Microsoft Excel and it gets the exact same answers that this formula does when it fits a power law, indicating that it, too, may be using this technique.
My question is, does anybody know where this formula came from? It looks as if they are doing a least-squares fit on a logarithmic scale, but is that right? I also haven’t seen that mentioned anywhere else in my travels. E.g. R has a package called igraph with a power.law.fit() function that uses a different technique (and strangely only yields one return value). Anybody know anything about this formula?